Four reasons instructional coaching is currently the best-evidenced form of CPD
At the ResearchEd 2018 National Conference, Steve Farndon, Emily Henderson and I gave a talk about instructional coaching. In my part of the presentation, I argued that instructional coaching is currently the best-evidenced form of professional development we have. Steve and Emily spoke about their experience of coaching teachers and embedding coaching in schools. This blog is an expanded version of my part of the presentation…
What is instructional coaching?
Instructional coaching involves an expert teacher working with a novice in an individualised, classroom-based, observation-feedback-practice cycle. Crucially, instructional coaching involves revisiting the same specific skills several times, with focused, bite-sized bits of feedback specifying not just what but how the novice needs to improve during each cycle.
In many ways, instructional coaching is the opposite of regular inset CPD, which tends to involve a broad, one-size-fits-all training session delivered to a diverse group of teachers, involving little practise and no follow-up.
Instructional coaching is also very different to what we might call business coaching, in which the coach asks a series of open questions to draw out the answers that people already, in some sense, know deep down. Instructional coaches are more directive, very intentionally laying a trail of breadcrumbs to move the novice from where they are currently, to where the expert wants them to be.
Some instructional coaching models include a rubric outlining the set of specific skills that a participant will be coached on. Others are even more prescriptive, specifying a range of specific techniques for the teacher to master. There are also a range of protocols or frameworks available to structure the coaching interaction, with Bambrick-Santoyo’s Six Step Model being among the most popular.
Examples of established instructional coaching programmes for teachers include the SIPIC programme, the TRI model, Content Focused Coaching and My Teaching Partner. In the UK, Ark Teacher Training, Ambition Institute and Steplab are three prominent users of instructional coaching.
What is the evidence for instructional coaching?
In 2007, a careful review of the literature found only nine rigorously evaluated CPD interventions in existence. This is a remarkable finding, which shows how little we knew about effective CPD just a decade ago.
Fortunately, there has been an explosion of good research on CPD since then and my reading of the literature is that instructional coaching is now the best-evidenced form of CPD we have. In the rest of the blog, I will set out four ways in which I think the evidence base for instructional coaching is superior.
Before I do, here are some brief caveats and clarifications:
- By “best evidenced”, I mean the quality and quantity of underpinning research
- I am talking about the form of CPD not the content (more on this later)
- This is a relative claim, about it being better evidenced than alternative forms (such as mentoring, peer learning communities, business-type coaching, lesson study, analysis-of-practice, etc). Remember, ten years ago, we knew very little about effective CPD at all!
- I am talking about the current evidence-base, which (we hope) will continue to develop and change in coming years.
Strength 1: Evidence from replicated randomised controlled trials
In 2011, a team of researchers published the results from a randomised controlled trial of the My Teaching Partner (MTP) intervention, showing that it improved results on Virginia state secondary school tests by an effect size of 0.22. Interestingly, pupils whose test scores improved the most were taught by the teachers who made the most progress in their coaching sessions.
Randomised controlled trials (RCT) are uniquely good at isolating the impact of interventions, because the process of randomisation makes the treatment group (those participating in MTP) and control group (those not) identical in expectation. If the two groups are identical, then any difference in outcomes must be the result of the one remaining difference – participating in the MTP programme. Unfortunately, the randomisation process does not guarantee the two groups are identical. There is a small chance that, even if MTP has zero effect on attainment, a well-run RCT will occasionally conclude that it has a positive impact (so-called random confounding).
This is where replication comes in. In 2015 the same team of researchers published the results from a second, larger RCT of the MTP programme, which found similar positive effects on attainment. The chances of two good trials mistakenly concluding that an intervention improved attainment, when in fact it had no effect, are far smaller than for a single trial. The replication therefore adds additional weight to the evidence base.
There are however, other CPD interventions with evidence from replicated RCTs, meaning this is not a unique strength of the evidence on coaching.
Strength 2: Evidence from meta-analysis
In 2018, a team of researchers from Brown and Harvard published a meta-analysis of all available studies on instructional coaching. They found 31 causal studies (mostly RCTs) looking at the effects of instructional coaching on attainment, with an average effect size of 0.18. The average effect size was lower in studies with larger samples, and in interventions that targeted general pedagogical approaches, however these were still positive and statistically significant.
A second, smaller meta-analysis looking at CPD interventions in literacy teaching also concluded that coaching interventions were the most effective in terms of increasing pupil attainment.
The evidence from the replicated MTP trials described above shows that good instructional coaching interventions can be effective. The evidence from meta-analysis reviewed here broadens this out to show that evaluated coaching programmes work on average.
How does this compare to other forms of CPD? There are very few meta-analysis relating to other forms of professional development, and those we do have employ weak inclusion criteria, making it hard to interpret their results.
Strength 3: Evidence from A-B testing
Instructional coaching is a form of CPD. In practice, it must be combined with some form of content in order to be delivered to teachers. This begs the question of whether the positive evaluation results cited above are due to the coaching, or to the content which is combined with the coaching. Perhaps the coaching component of these interventions is like the mint flavouring in toothpaste: very noticeable, but not in fact an active ingredient in bringing about reduced tooth decay.
In February 2018, a team of researchers from South Africa published the results from a different type of randomised controlled trial. Instead of comparing treatment and control groups, they compared a control group to A) a group of teachers trained on new techniques for teaching reading at a traditional “away day” and B) a group of teachers trained on the exact same content using coaching. This type of A-B testing provides an opportunity to isolate the active ingredients of an intervention.
The results showed that pupils taught by teachers given the traditional “away day” type training showed no statistically significant increase in reading attainment. By contrast, pupils taught by teachers who received the same content via coaching improved their reading attainment by an effect size of 0.18. The coaching was therefore a necessary component of the training being effective. A separate A-B test in Argentina in 2017 also found coaching to be more effective than traditional training on the same content.
Besides these two coaching studies, there are very few other A-B tests on CPD interventions. Indeed, a 2017 review of the A-B testing literature found only one evaluation which found different results for the two treatment comparisons – a joint analysis-of-practice of video cases programme. While very promising, this analysis-of-practice intervention does not yet have evidence from replicated trials or meta-analysis.
Strength 4: Evidence from systematic research programmes
A difficulty in establishing the superiority of one form of CPD is that you need to systematically test the other available forms. The Investing in Innovation (I3) Fund in the US does just this by funding trials on a wide range of interventions, as long as they have some evidence of promise. Since 2009, they have spent £1.4Bn testing 67 different interventions.
The chart below shows the results from 31 RCTs investigating the impact of interventions on English attainment (left chart) and a further 23 on maths attainment (right chart). Bars above zero indicate a positive effect, and vice versa. Green bars indicate a statistically significant effect and orange bars indicate an effect which, statistically speaking, cannot be confidently distinguished from zero. [i]
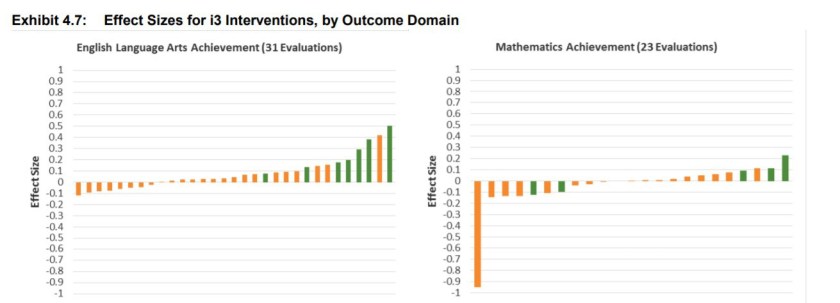
Two things stand out from this graph. First, most interventions do not work. Just seven out of thirty-one English and three out of twenty-three maths interventions had a positive and statistically significant effect on pupil attainment. This analysis provides a useful approximation of what we can expect across a broad range of CPD interventions.[ii]
In order to compare instructional coaching with the evidence from I3 evaluations, I constructed an identical chart including all the effect sizes I could find from school-age instructional coaching evaluations. The chart (below) includes all the relevant studies from the Kraft et al meta-analysis for which effect sizes could be straightforwardly extracted [iii], plus three additional studies [iv]. Of the sixteen studies included, eleven showed positive, statistically significant impacts on attainment. This compares very favourably to I3 evidence across different forms of CPD.

Conclusion
Instructional coaching is supported by evidence from replicated randomised controlled trials, meta-analysis, A-B testing and evidence from systematic research programmes. I have looked hard at the literature and I cannot find another form of CPD for which the evidence is this strong.
To be clear, there are still weaknesses in the evidence base for instructional coaching. Scaled-up programmes tend to be less effective than smaller programmes and the evidence is much thinner for maths and science than for English. Nevertheless, the evidence remains stronger than for alternative forms of CPD.
How should school leaders and CPD designers respond to this? Where possible, schools should strongly consider using instructional coaching for professional development. Indeed, it would be hard to justify the use of alternative approaches in the face of the existing evidence.
Of course, this will not be easy. My co-presenters Steve Fardon and Emily Henderson, both experienced coaches, were keen to stress that establishing coaching in a school comes with challenges.
Unfortunately, in England, lesson observation has become synonymous with remedial measures for struggling teachers. Coaches need to demonstrate that observation for the purposes of instructional coaching is a useful part of CPD, not a judgement. I have heard of one school tackling this perception by beginning coaching with senior and middle leaders. Only once this had come to be seen as normal did they invite classroom teachers to take part.
Another major challenge is time. Emily Henderson stressed that if coaching sessions are missed it can be very hard to get the cycle back on track. Henderson would ensure that the coaching cycle was the first thing to go in the school diary at the beginning of the academic year and she was careful to ensure it never got trumped by other priorities. Some coaching schools have simply redistributed inset time to coaching, in order to make this easier.
Establishing coaching in your school will require skilled leadership. For the time being however, coaching is the best-evidenced form of professional development we have. All schools that aspire to be evidence-based should be giving it a go.
Follow me: @DrSamSims
UPDATE: If you want to read more about IC, I recommend Josh Goodrich’s blog series here.
[i] I wouldn’t pay too much attention to the relative size of the bars here, since attainment was measured in different ways in different studies.
[ii] Strictly speaking, only 85% of these were classed as CPD interventions. The other 15% involve other approaches to increasing teacher effectiveness, such as altering hiring practices. It should be noted that the chart on the left also includes some coaching interventions!
[iii] It should be noted that I did not calculate my own effect sizes or contact original authors where effect sizes were not reported in the text. To the extent that reporting of effect sizes are related to study findings, this will skew the picture.
[iv]
Albornoz, F., Anauati, M. V., Furman, M., Luzuriaga, M., Podesta, M. E., & Tayor, I. (2017) Training to teach science: Experimental evidence from Argentina. CREDIT Research Paper.
Bruns, B., Costa, L., Cunha, N. (2018) Through the looking glass: Can classroom observation and coaching improve teacher performance in Brazil? Economics of Education review. 64, 214-250.
Cilliers, J., Fleisch, B., Prinsloo, C., Reddy, V., Taylor, S. (2018) How to improve teaching practice? Experimental comparison of centralized training and in-classroom coaching. Working Paper.
